
회사에서 다른 분이 RAG 논문 내용을 공유해주셨습니다. 공유받은 내용을 기반으로 다시 정리해보려고 합니다. 먼저 이 세미나로 새로 배울 수 있던 내용은 다음과 같습니다.
- Parametric and Non-Parametric
- 서로 다른 임베딩 모델을 사용해 유사도(내적)를 구하는 것도 가능하다. (Transformer Q, K, V와 연계)
- Beam Search
논문 내용을 주로 다루면서 위 개념에 대해서도 언급해보도록 하겠습니다.
Issue
교육, 법률, IT 등 특정 전문 지식이 필요한 자연어 모델의 성능을 끌어 올리거나 ChatGPT처럼 다양한 주제로 대화를 나눌 수 있지만 가끔은 없는 사실을 마치 있는 것처럼 말하는 현상(Hallucination)을 줄이려면 어떻게 해야 할까요? 바로 질문(Query)와 관련된 문서(Document)를 참고해서 답변하면 될 것 같습니다. 질문과 관련된 문서를 찾고(Retrieval) 질문과 관련 문서를 같이 언어 모델에 넣어주는 것이 바로 RAG 방법론입니다. 관련 문서는 어떻게 찾고, 언어 모델에는 어떻게 입력하는지 구체적으로 살펴보겠습니다.
Architecture

위 그림에 RAG 구조가 그려져 있습니다. 크게 보자면 RAG는 Retriver와 Generator로 구성되어 있습니다. Retriver는 질문과 관련된 문서를 찾는 모듈입니다. Retriver에서는 쿼리 임베딩 모델(q), 문서 임베딩 모델(d)를 이용합니다. 두 모델을 이용해 쿼리와 문서를 임베딩하고, 쿼리와 내적한 값이 높은 문서를 찾습니다.
내적 값이 가장 높은 문서를 4개 정도 찾았다면(문서 수는 정할 수 있습니다), 개별 문서 뒤에 쿼리를 붙여 Generator에 4번 입력합니다. Generator output도 4개가 나올 것이고 이 중 소프트맥스 확률 값이 가장 높은 결과를 사용합니다.
Parametric and Non-Parametric

논문에서는 Retriever를 Non-Parametric, Generator를 Parametric이라고 합니다. Parametric은 평균과 표준편차만 주어지면 확률 분포가 정해지는 정규 분포처럼 정해진 개수의 파라미터에 의해 분포가 고정되는 모델을 의미합니다. Neural Network도 Parameter 수가 고정되어 있고, 학습에 의해 파라미터 값을 업데이트하면 분포가 바뀌게 됩니다. Non-Parametric은 데이터가 특정 분포를 따른다고 가정하지 않고, 튜닝할 파라미터가 없습니다. KNN처럼 Subset에 데이터가 추가되거나 빠지면서 결과가 달라지거나, Decision Tree처럼 데이터에 따라 분기점, 깊이 등이 달라지는 경우가 있습니다. Retriever에서도 임베딩한 문서가 많거나 적어짐에 따라 Retrieve 결과가 바뀔 수 있습니다.
Train
Which models are trainable?
RAG에서는 총 3개의 모델을 사용합니다. Retriver에서 쿼리 임베딩 모델과 문서 임베딩 모델, Generator 언어 모델입니다. 이 중 문서 임베딩 모델은 학습하지 않고, 쿼리 임베딩 모델과 Generator만 학습합니다. 문서 임베딩 모델을 학습하지 않는 이유는 문서 임베딩 모델이 업데이트될 때마다 벡터 DB에 저장된 문서를 모두 업데이트해야하기 때문입니다.
서로 다른 임베딩 모델을 사용해 두 벡터 사이의 유사도를 구해도 괜찮은가?
Transformer에서 Q만 업데이트하고 K는 업데이트하지 않는데도, Q Transform 벡터와 K Transform 벡터를 이용해 Attention을 구합니다. 수학적, 연역적으로 서로 다른 임베딩 모델을 사용해도 되는지는 모르지만, Transformer와 본 논문에서 나타나는 결과를 보았을 때 서로 다른 임베딩 모델을 이용해도 둘 사이의 벡터 유사도를 구할 수 있다고 결론내릴 수 있습니다. 아래 실험 결과에서도 쿼리 임베딩 모델을 Frozen한 경우(두번째 행)보다 학습 시킨 경우(세번째 행)이 10개 Task 모두 더 좋은 성능을 보였습니다.

Marginalize Outputs : Sequence-wise VS Token-wise
학습에 사용할 Model Output은 여러 문서에서 뽑은 Output 중에 가장 좋은 것 하나만을 사용할 수도 있지만, 논문에서는 모든 문서를 활용해서 최종 Output을 만듭니다. 이때 문서별 Output을 섞는 방법으로 두 가지를 제안합니다. 첫 번째 방법은 Sequence 단위로 섞는 방법입니다. 문서를 하나씩 사용해서 Output Sequence를 뽑아내면 문서 개수만큼 Sequence Distribution(pθ)이 생깁니다. 모든 Sequence Distribution(pθ)을 내적값( pη)을 가중치로 더해준 값을 최종 Sequence Distribution으로 사용합니다.

두번째 방법은 토큰 단위로 섞습니다. 다음 예측할 토큰 위치에 문서별로 생성한 토큰 Probability Distribution(pθ)을 내적값( pη)으로 가중합해 사용하고, 그 다음 토큰을 예측할 때 가중합한 토큰 Probability Distribution을 사용합니다.
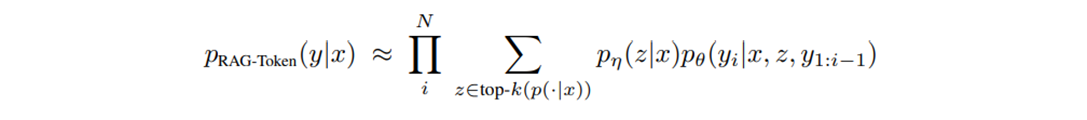
Decoding
Beam Search

Greedy Search는 모든 경우의 수를 탐색해 최적의 경우를 선택하는 방식입니다. Beam Search는 모든 경우의 수 중에 가장 적합한 경우를 n개 선택합니다. 위 그림은 n이 3인 Beam Search를 언어 모델에 적용한 그림입니다. Start 노드를 기점으로 다음 분기에 확률값이 높은 a, I, the 세 개의 토큰이 선택되었습니다. 다음 분기에는 세 토큰 다음에 올 토큰을 3개씩 뽑습니다. 총 9개의 노드가 선택되었습니다. 그 다음 분기에서 9개 노드를 활용해 다음 토큰을 예측하지 않고, 9개 노드까지의 확률 평균값이 가장 높은 3개의 sequence를 선택합니다. 그 결과 'a cat', 'I am', 'the dog'가 선택되었습니다. max_seq_length까지 이러한 방식으로 token을 생성한 다음. 최종 9개 sequence 중에 가장 확률값이 높은 sequence를 선택하게 됩니다.
Softmax 확률값이 가장 높은 토큰을 선택해서 텍스트를 생성하는 기존 방법은 Greedy Search인데, 이 경우 초기 선택은 최선일 수 있지만, 완성된 Sequence는 최선이 아닐 수 있다는 문제가 있습니다. 위 그림에서 매 분기마다 확률값이 큰 노드가 위에, 작은 노드가 아래에 위치한다고 가정했을 때, Greedy Search로 생성한 문장은 "a cat meowed' 입니다. 하지만 3-Beam Search로 생성한 결과인 'the dog barked suddely'의 평균 확률이 더 높습니다.
Beam Search + Marginalize
토큰 단위로 문서별 결과를 섞는(Marginalize) 방법은 토큰마다 확률분포를 Beam-Search에 적용하면 됩니다. 3개의 노드를 고를 때 문서별로 결과를 섞은 확률 분포에서 고르는 것입니다.
문제는 Sequence 단위입니다. 토큰을 생성할 때마다 Sequence 확률 분포를 비교해야 하는 Beam search와 달리 Sequence 단위로 Marginalize하는 것은 토큰 단위로는 별다른 조작을 하지 않고 문서별로 Sequence를 끝까지 생성하기 때문입니다. 논문에서는 Beam Search의 아이디어를 적용할 방법을 새로 고안했습니다. 아래 그림에서보면 3개의 문서 z1, z2, z3에 대해 Sequence를 3개씩 고릅니다. 9개의 문장 중 가장 적합한 Output을 고르기 위해서 점수를 매깁니다. 점수는 각 문장마다 z1, z2, z3 문서를 사용해서 생성될 확률을 더한 것입니다. 아래 그림에서는 9개 문장 중 4개가 중복됩니다. 첫 번째 문장은 세 문서에서 생성한 문장에 모두 포함됩니다. 따라서 바로 확률값을 구할 수 있습니다. 하지만 두번째 문장 이후로는 특정 문서에서는 생성되지 않았습니다. 즉 p(y2|x. z2)처럼 빨간색 확률값이 없다는 의미입니다. 이 확률값을 다시 구하기 위해서는 문서별로 'RAG is NLP'가 나올 확률을 다시 계산해야 합니다. 계산량을 줄이기 위해서 단순히 0으로 치환하는 방법도 있습니다. 전자를 Thorough Decoding이라 하고, 후자를 Fast Decoding이라 합니다. 일반적인 상황에서는 서로 다른 문서에서 생성한 문장이 겹칠 일은 거의 없어 보이기 때문에, 두 방법 간의 차이가 크지 않을 것 같습니다.

Experiments
흥미로운 실험 결과만 하나 소개합니다. 몇 개의 문서를 Retrive하는 것이 좋은지 알아보기 위해 NLP Task별로 문서개수에 따라 성능이 어떻게 변화하는지 실험했습니다.대체로 10개 내외에서 가장 좋은 성능을 보이거나 그 이후로는 성능 개선이 크게 없어보입니다.

'AI > 자연어' 카테고리의 다른 글
| [칼럼읽기] Open-source DeepResearch – Freeing our search agents (0) | 2025.02.25 |
|---|---|
| 오픈 소스를 활용한 RAG 구현 (0) | 2024.01.16 |
