요약
- Few-Shot Learning에서 사용하는 Neural Network는 Support Set과 관계없이 학습(Pretrain)된다.
- Support Set에 대해 Fine Tune을 하면 Few-Shot Learning의 성능을 높일 수 있다.
- 이외에도 Regularization, Innitialization, Cosine Similiarity를 이용해 Few-Shot Learning의 성능을 개선할 수 있다.
Base Category에 대해 Pretrain된 네트워크 f(x)가 있다. f(x)를 Support Set에 Fine Tune하는 가장 간단한 방법은 Classifier를 추가하는 것이다.
- p (prediction) = Softmax( W · f(x) + b)
A Good Initialization : W = M and b = 0
이때 W를 random initalize하는 것보다 좋은 방법이 있다. Support Set에 포함된 클래스마다 feature vector (μ)를 계산해 합치는 것이다.

Entropy Regularization
Support Set에 Fine Tune할 때 난관은 Overfitting이다. Support Set이 충분히 많지 않기 때문이다. 이때 사용할 수 있는 방법 중 Entropy Regularization이 있다.
- p (prediction) = Softmax( W · f(x) + b), x = query image
- Entropy H(p) = - ∑ p¡ · log p¡, i = support image
- Entropy Regularization: average of H(p)
쿼리 이미지(x)가 i 클래스일 확률(p¡)에 대한 엔트로피 H(p)를 구한 후 모든 쿼리 이미지에 대해 평균을 내면 Entropy Regularization을 구할 수 있다. 이 값이 작아지도록 Loss에 추가해 학습하면 Overfitting을 막을 수 있다.
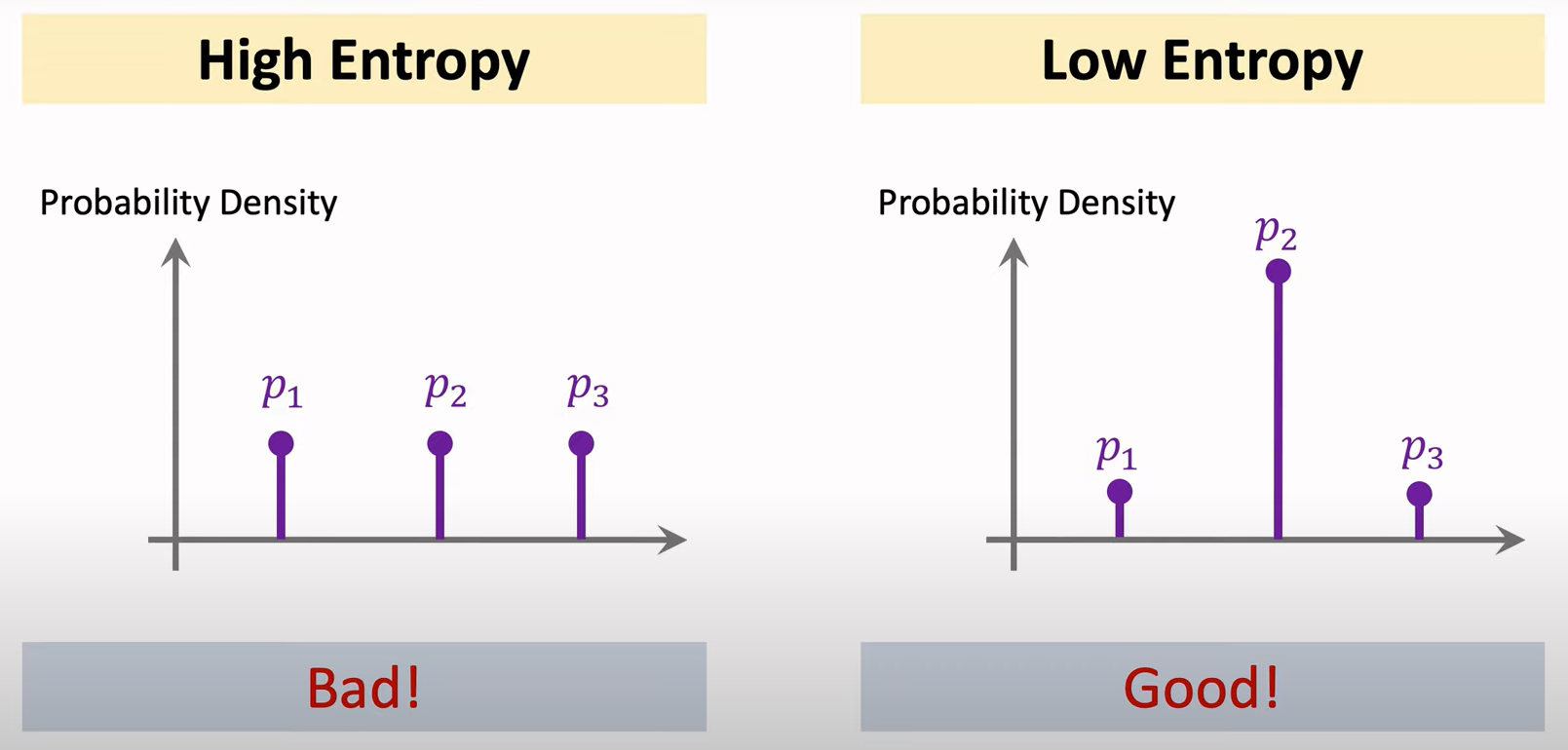
위 그림에서 왼쪽 그래프는 클래스 1, 2, 3에 대한 예측 확률이 비등하다. 반면 오른쪽 그래프는 두번째 클래스의 예측 확률이 높다. Entropy를 계산하면 오른쪽 그래프가 더 낮게 나온다. 즉, Entropy Regularization를 이용하면 오른쪽 그래프와 같이 예측하도록 파라미터를 업데이트할 수 있다.
Cosine Similarity + Softmax Classifier

Softmax Classfier에서 W와 q의 내적을 W와 q의 Cosine Similarity로 치환할 수 있다. Cosine Similarity는 W와 q의 내적을 정규화한다는 차이점이 있다.
참고 : https://www.youtube.com/watch?v=U6uFOIURcD0
'AI > 메타 러닝' 카테고리의 다른 글
| [Image Classification] One-Shot Learning (0) | 2022.12.23 |
|---|---|
| Transfer Learning VS Few-Shot Learning (0) | 2022.12.22 |
| 메타 러닝 (Meta Learning) (0) | 2022.12.19 |


