2015년 U-Net 발표 이후에 메디컬 분야의 이미지 세그멘테이션 연구는 U-Net을 기본 골자로 하는 경우가 많았다. U-Net++도 마찬가지로 U-Net 아키텍처를 업그레이드해 시멘틱 세그멘테이션 성능을 끌어올렸다.
U-Net 복습

베이스라인 모델인 U-Net을 잠시 복기해보자. U-Net은 바이오 이미지의 시멘틱 세그멘테이션을 목적으로 고안되었다. 특징으로는 첫째, 인코더-디코더 형식으로 아키텍처의 전체적인 형상이 좌우 대칭의 U자 모양을 그린다는 점이 있다. 그림 1을 보면 각각 4번의 다운 샘플링과 업 샘플링을 하는 것을 볼 수 있다. 두번째는 Skip Connection이다. 그림 1의 회색 화살표는 인코더의 특징맵을 대응하는 디코더의 특징맵과 합치는 것을 의미한다. 특징맵을 합칠 때는 단순히 특징맵의 채널 수준에서 이어붙인다(Concatenation).
U-Net 성능 끌어올리기
최적화 포인트
U-Net의 성능을 끌어올리기 위해서 최적화할 수 있는 포인트가 무엇인지 살펴보자.
U-Net을 비롯한 대부분의 세그멘테이션 모델이 인코더-디코더 아키텍처를 따른다. 인코더-디코더 아키텍처의 문제점은 얼마나 깊어야(다운샘플링을 얼마나 많이 해야) 최적의 성능을 낼 수 있는지 알기 힘들다는 것이다. 심지어 어떤 문제에 U-Net을 적용하느냐에 따라 최적의 깊이는 달라질 수 있다. 예를 들어 아래 그림 2에 다양한 깊이의 U-Net 모델이 제시되어 있고, 표1에 EM, Cell, Brain Tumor 데이터셋을 대상으로 각 모델의 성능을 평가했다. Cell과 Brain Tumor 세그멘테이션 문제에서는 상대적으로 얕은 모델인 U-Net(L3)의 성능이 가장 좋았고, EM 데이터셋에 대해서는 모델이 깊을수록 성능이 좋아졌다.

Q. 인코더의 깊이에 따른 모델의 특징
본 논문에서는 깊이를 다양하게 가져가면서 다양한 크기의 객체를 세그멘테이션하는 성능을 개선할 수 있다고 했다.

최적의 깊이를 알 수 없다면 생각해볼 수 있는 것은 앙상블이다. 앙상블은 여러 가지 모델의 결과를 모아 더 나은 결과를 내는 방법으로 U-Net도 깊이에 따라 여러 모델을 만든 후 모든 결과를 합쳐 최선의 결과를 낼 수 있다. 그림 2의 U-Net(L1)부터 U-Net(L4)까지 깊이만 다른 U-Net 모델들을 각각 학습해 앙상블하는 간단한 방법을 적용하는 것이다. 하지만 이러한 방법은 굉장히 비효율적이다. 왜냐하면 인코더를 공유하고 있지 않기 때문이다. 독립적으로 앙상블할 모델들을 학습하는 것은 멀티 태스크 학습의 이점을 제대로 활용핮 못한다.(이 부분은 참조 논문 [5], [6]를 살펴볼 필요가 있다)
두번째로 짚어볼 포인트는 Skip connection이 대응하는 인코더의 피쳐맵만 활용한다는 것이다. 이는 인코더의 특징맵을 활용하는 데 있어 불필요한 제한이다. 인코더-디코더 구조에서 같은 크기의 특징맵은 의미적으로(semantically) 같다고 할 수 없고, Skip Connection에서 같은 크기의 특징맵을 합쳐야 한다는 명확한 근거 이론이 없다.
앙상블 with deep supervision
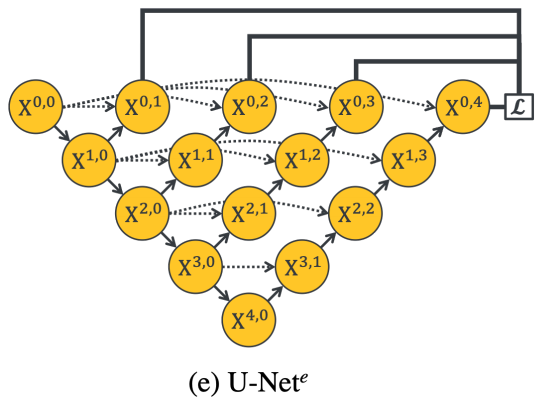
앞서 다양한 깊이의 U-Net 모델을 개별적으로 학습해 앙상블하는 것은 인코더를 공유하고 있지 않는 모델들의 결과를 합치는 것이기 때문에 비효율적이라 했다. 본 논문에서는 앙상블 방법을 적용하면서도 개별 모델들이 인코더를 공유할 수 있는 구조를 제시한다. 그 형상은 그림 3과 같다. 그림 3의 U-Net(e)는 그림 2의 U-Net(L1)부터 U-Net(L4)를 앙상블한 모델이다. 보통의 앙상블은 개별 모델을 따로 학습하는 것과 다르게 U-Net(e)는 개별 모델들이 통합된 아키텍처다. 이때 본 논문에서는 통합 아키텍처를 만들기 위해 deep supervision 개념을 언급한다.
deep supervision은 깊은 이미지 분류 네트워크, 깊은 이미지 세그멘테이션 네트워크에서 사용되었다. 최종 아웃풋 외에 네트워크 중간 층의 결과 특징맵을 활용해 보조 손실 함수를 정의하는 방법으로, deep supervision을 이용하면 기울기 소실/폭발 문제를 해결하고, 과적합 방지에 도움이 된다고 한다.[4] deep supervision을 활용한 다른 인코더-디코더 아키텍처에서는 X(3,1), X(2,2), X(1,3) 등 디코더의 아웃풋을 활용해 보조 손실 함수를 정의했지만, 본 논문의 U-Net(e)에서는 U-Net(L1)부터 U-Net(L3)의 아웃풋 격인 X(0,1), X(0,2), X(0,3), X(0,3)를 활용해 보조 손실 함수를 정의한다. 인코더를 공유하는 앙상블 모델을 만들기 위한 변형인 듯하다. 추론할 때는 X(0,1)부터 X(0,4)까지 개별 U-Net모델의 아웃풋을 평균한다. 다시 말해, 학습할 때는 인코더를 공유하는 통합된 아키텍처를 학습한 후에 추론과정에서는 개별 모델의 결과를 모두 이용하는 앙상블 모델인 것이다.
Q. U-Net 이외에 deep supervision에서 중간층의 특징맵으로 손실함수를 정의할 때, image classification은 전체 class 수에 맞게 fc layer를 사용하고, image segmenation은 특징맵의 차원수(사이즈, 채널)를 맞춰주기 위해 업샘플과 1x1conv를 이용하는 것인가?
연구진은 U-Net(e) 앙상블 모델에서도 두가지 문제점을 언급한다. 첫번째는 개별 모델의 디코더끼리 연결되어 있지 않다는 것이다. 따라서 깊은 U-Net의 학습이 더 얕은 U-Net의 학습에 영향을 미치지 않는다. 두번째는 아직도 Skip Connection의 대상은 스케일이 같은 특징맵으로 제한되어 있다는 것이다. 다시 말하자면, 같은 크기의 특징맵을 합치는 것이 최적이라는 보장은 어디에도 없다. 이 두가지 문제점을 해결하기 위해 다시 한번 U-Net+라는 새로운 아키텍처를 제시한다.
Q. 디코더끼리 연결되어야 하는 이유는 무엇인가? 일단 이렇게 하면 성능은 좋아지는 것으로 보인다.
Short Skip Connection
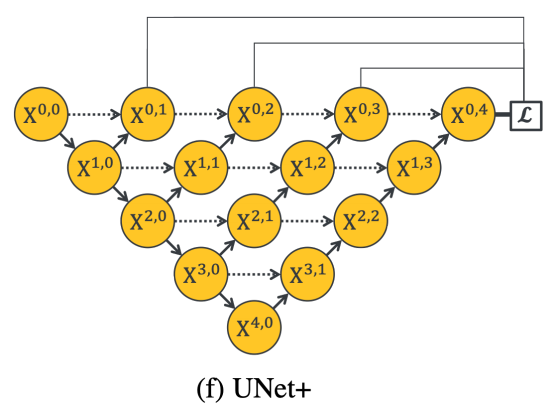
U-Net+의 가장 큰 특징은 기존 U-Net의 긴 Skip Connection을 없애고, 인접한 두 노드를 연결(Concatenation)했다는 것이다. 이렇게 함으로써 U-Net(L1)~U-Net(L4) 모델의 디코더가 연결되었고, 오차 역전파를 계산할 때 깊은 모델의 디코더의 기울기를 얕은 모델의 디코더로 보낼 수 있게 되었다. 또한 기존의 Skip connection에서 특징맵의 크기가 같은 것 끼리만 묶었다면, U-Net+에서는 이 제약이 조금 더 완화되었다. 디코더의 개별 노드에게 더 얕은 모델들의 특징맵을 모두 합한 결과가 전달되기 때문이다. 즉, 디코더의 특징맵보다 더 작은 특징맵이 Skip connection으로 전달된다는 것이다.
Final Architecture with dense connectivity
U-Net+도 베이스라인 U-Net과 U-Net(e)에 비하면 Skip Connection에서 같은 크기의 특징맵만 합쳐야 한다는 제약이 많이 줄어들었지만 아직 개선의 여지가 남아있는 것처럼 보인다. 마지막으로 본 논문에서는 개별 노드들끼리 더 촘촘하게 연결하는 dense connectivity를 도입한다.

dense connectivity를 도입한 U-Net++는 인접한 두 노드만 연결하는 것이 아니라, 같은 스케일의 특징맵을 모두 연결한다. 즉 그림 5의 같은 행에 있는 노드들을 모두 연결한다는 것이다. 패턴을 보자면 i가 0부터 4, j는 0부터 4-i라고 할 때X(i, j) 특징맵은 X(i, j+1)부터 X(i, 4-i)에 모두 전달한다.
Deep Supervision과 가지치기(Pruning)
사실 U-Net(e)와는 다르게 디코더가 연결된 U-Net+와 U-Net++에는 deep supervision을 이용할 필요가 없다. 하지만 deep supervision을 이용하면 추론할 때 가지치기(pruning)를 할 수 있어 계산 속도가 빨라지기 때문에 결국에는 deep supervision을 이용한다. U-Net++의 예시를 살펴보자.

deep supervision으로 U-Net++를 학습할 경우 여러개의 X(0,j) 노드에서 세그멘테이션 결과를 낼 수 있다. 이는 곧 추론할 때 가지치기를 가능하게 한다. U-Net++(L4)처럼 X(0,4)에서 세그멘테이션 결과를 낼 경우에는 가지치기를 하지 않은 것이다. 반면에 U-Net++(L1)은 최대한으로 가지치기를 해 X(0,1)에서 결과를 낸다.
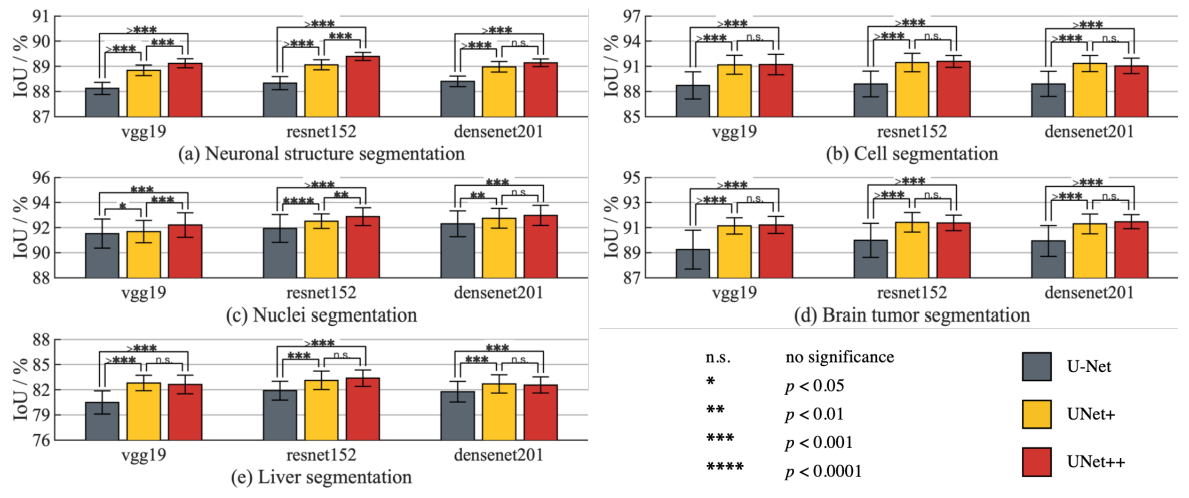
deep supervision으로 학습한 U-Net++는 두 가지 모드를 지원한다. 하나는 앙상블 모드, 다른 하나는 가지치기 모드다. 앙상블 모드는 U-Net++(L1)부터 U-Net++(L4)의 결과를 평균한다. 가지치기 모드는 U-Net++(L1)부터 (L4)까지 모델 중에 하나를 선택해 결과를 낸다. 아래 그림 7을 보면 가지치기를 할 경우 U-Net++ L4까지 사용하지 않고도 비슷한 성능을 내면서, 추론 속도를 단축할 수 있다. (아쉽게도 논문에서는 앙상블 모드와 비교는 없다.)

Embedded vs. isolated training of pruned models
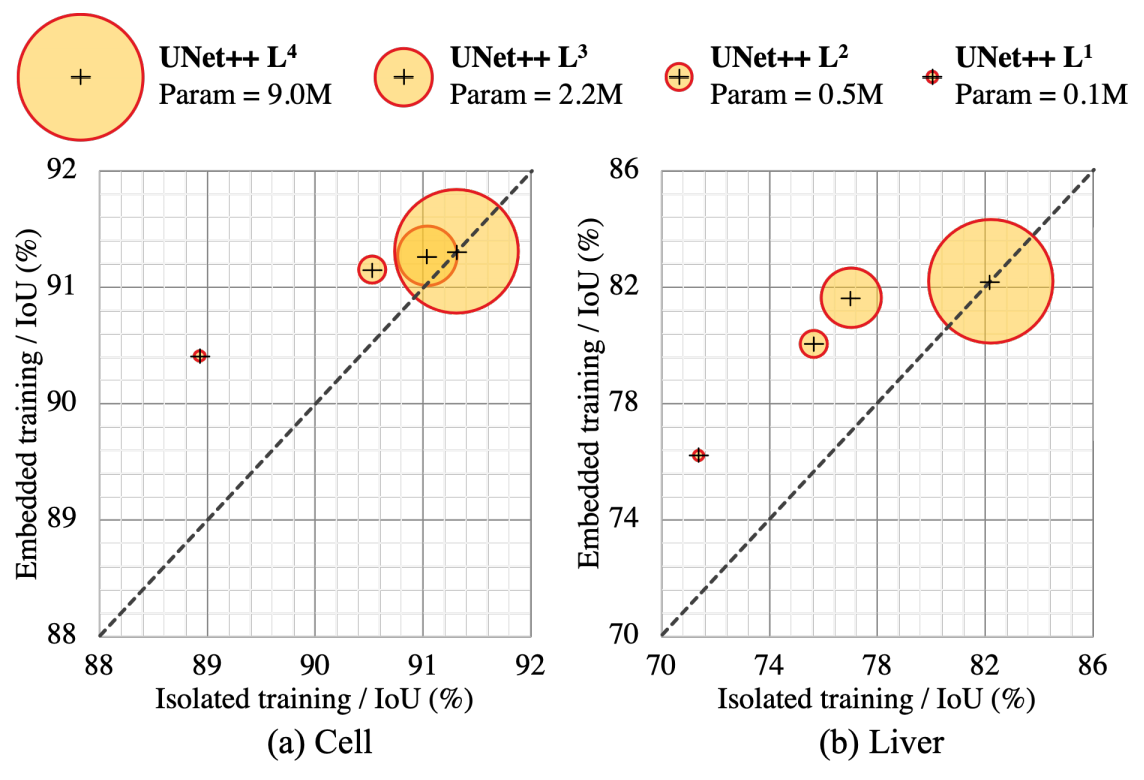
이론적으로 U-Net++(Ld)를 학습하는 방법은 두 가지가 있다. 첫번째는 U-Net++ 모델을 학습한 다음 d 수준의 깊이만큼 가지치기를 하는 방법이고, 두번째는 처음부터 d 수준의 깊이의 U-Net++(Ld)모델을 학습하는 것이다. 두번째 방법은 d보다 깊은 디코더와 상호작용이 없다.
첫번째 방법을 임베딩 학습, 두번째 방법을 독립 학습이라 하자. 그림 8을 보면 임베딩 학습과 독립 학습이 동일하게 U-Net++모델 전체를 학습하는 U-Net++(L4)모델을 제외하고는 임베딩 학습의 결과가 더 좋다는 것을 알 수 있다. 특히 (a) cell 데이터셋에 대해서는 가지치기를 많이 할수록 두 학습 방법의 성능 차이가 커진다.
특징맵 시각화

성능



참고
deep supervision 손실함수

데이터셋 정보

Upsample

Reference
[1] Olaf Ronneberger, Philipp Fischer, Thomas Brox. U-Net: Convolutional Networks for Biomedical Image Segmentation. In arXiv, 2015
[2] Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima Tajbakhsh, and Jianming Liang. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. arXiv:1807.10165v1 [cs.CV] 18 Jul 2018
[3] Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima Tajbakhsh, and Jianming Liang. UNet++: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. arXiv:1912.05074v2 [eess.IV] 28 Jan 2020
[4] C.-Y. Lee, S. Xie, P. Gallagher, Z. Zhang, and Z. Tu, “Deeply-supervised nets,” in Artificial Intelligence and Statistics, 2015, pp. 562–570.
[5] Y. Bengio et al., “Learning deep architectures for ai,” Foundations and trends R in Machine Learning, vol. 2, no. 1, pp. 1–127, 2009.
[6] Y. Zhang and Q. Yang, “A survey on multi-task learning,” arXiv preprint arXiv:1707.08114, 2017.
'AI > 비전' 카테고리의 다른 글
| [SEGMENTATION] DeepLab v2 | 2016 (0) | 2021.08.03 |
|---|---|
| [SEGMENTATION] Attention U-Net: Learning Where to Look for the Pancreas (0) | 2021.07.20 |
| [SEGMENTATION] DeepLab v1 | 2015 (0) | 2021.06.21 |
| [SEGMENTATION] U-Net: Convolutional Networks for Biomedical Image Segmentation | 2015 (0) | 2021.06.05 |
| Image Scale(척도)과 resolution(해상도) (1) | 2021.05.30 |



