메타 러닝 (Meta Learning)
자동화와 AutoML
규칙적인 작업은 자동화할 수 있습니다. AI가 위협하는 사람의 일자리 1순위가 바로 규칙적이고 반복적인 작업을 하는 일자리입니다. 심지어는 사람이 발견하기 어려운 규칙도 AI는 찾아낼 수 있습니다. 그러니 우리의 일자리가 언제 빼앗길지 모른다는 불안감이 더 커집니다. 그렇다면 과연 AI를 만드는 일도 자동화로부터 안전할 수 있을까요?
AI는 '만든다'고 표현하지 않고 '학습한다'고 표현합니다. '기계 학습' 방법론이 AI 기술의 발전을 이끌고 있기 때문입니다. 따라서 AI 연구자들은 AI를 어떻게 하면 더 나은 AI를 학습할 수 있는지 연구합니다. 그런데 꽤 오래 전부터 AI를 만드는 일도 자동화하는 시도가 있었습니다. AI를 학습하는 과정이 다양한 조합을 시도해보는 반복적인 작업이기 때문입니다. 이렇게 AI를 자동으로 학습하는 분야를 AutoML이라고 합니다.
AutoML과 메타 러닝
메타 러닝은 AutoML을 이야기할 때 빠질 수 없는 연구 분야입니다. "Learn how to learn"이라는 문장으로 설명하는 메타 러닝은 "어떻게 AI를 학습에야 성능 좋은 AI가 나오는지 배우는 것"이라고 할 수 있습니다. "어떻게 학습할 것인가?"는 "하이퍼 파라미터를 어떻게 설정할 것인가"와 동일한 질문입니다. 즉 하이퍼 파라미터의 구성(Configuration)을 설정하는 것이 "Learn how to learn"에서 "how to learn"에 해당합니다.
하이퍼 파라미터에 대해 설명해보겠습니다. AI로 해결해야 할 문제가 주어졌다고 생각해봅시다. 지도 학습을 이용하기로 결정하고, 문제를 해결할 수 있는 데이터 세트를 준비합니다. 그리고 어떤 알고리즘, 비용(손실) 함수, 최적화 방법을 사용할지 정합니다. 여기서 끝나지 않고 선택한 알고리즘, 비용 함수, 최적화 방법에 따라오는 세부적인 설정도 정해야 합니다. 예를 들어 Decision Tree는 노드의 수나 깊이를 선택해야 하고, Neural Network를 사용한다면 노드 수, 층의 깊이 등을 선택해야 합니다. 최적화 방법도 경사하강법을 선택했다면 학습률을 선택해야 하고, 추가적으로 Momentum 계수나 Weight Decay 값을 설정하기도 합니다. 이렇게 사람이 일일이 설정해 주는 값을 하이퍼 파라미터(Hyper Parameter; 초매개변수)라고 합니다.
메타 러닝에는 아래와 같이 크게 3가지 구분이 있습니다.
- Learn from Model Evaluation
- Learn from Meta Feature
- Learn from Prior Model
본 글에서는 위 세 가지 메타 러닝 방법에 대해 개념적인 설명을 해보겠습니다.
Learn from Model Evaluation
참고 : https://www.youtube.com/watch?v=AO4ZeDPKXg4&list=PLCsebpDZm0n6-COSyAcfr70uiUZObzF-Q&index=33
Task Independent Recommendation
| Configuration 1* | Configuration 2* | Configuration 3* | |
| Task 1 | Performance Rank (1) | Performance Rank (2) | Performance Rank (3) |
| Task 2 | Performance Rank (2) | Performance Rank (1) | Performance Rank (3) |
| Task 3 | Performance Rank (2) | Performance Rank (3) | Performance Rank (1) |
| Global Optimal Rank | 1 | 3 | 2 |
Configuration*i는 Task i에 최적인 Local Optimal Configuration입니다.
Task Independent Recommendation은 새로운 Task에 대해서 어떤 Configuration이 가장 좋을지 추천해주는 로직입니다. 이름에서 알 수 있는 것처럼 새로운 Task가 무엇인지 상관없이 보편적으로 좋은 성능을 보이는 Configuration을 추천해줍니다.
과거에 Task 1, 2, 3에 대해 실험한 경험이 있다고 할 때, 베이지안 최적화 등을 통해 각 Task마다 가장 최적의 Configuration을 찾습니다. 위 표는 기존에 Task1, 2, 3에 대해서 Configuration 1, 2, 3로 학습을 한 성능표입니다. Task마다 어떤 Configuration이 좋은 성능을 보였는지 순위를 매겨본 결과 Configuration1이 Task2, 3에서 가장 좋은 성능을 보였습니다. (Global Optimal Rank는 Local Rank를 단순 평균을 낼 수도 있고, Quasi-linear ranking이나 베이지안 최적화 등 복잡한 방법을 사용할 수도 있습니다.) 따라서 Configuration1이 보편적으로 좋은 성능을 보이기 때문에 새로운 Task가 주어진다면 Configuration1을 추천합니다.
다음과 같이 Task의 예시를 들 수 있다. 모든 Task는 이미지를 분류하는 Task이며 Task1은 이미지넷 데이터셋이고, Task2는 질병 여부를 진단하는 데이터셋, Task3는 견종을 분류하는 데이터셋이다. 새로운 Task는 차종을 분류하는 데이터셋이라고 생각해볼 수 있다.
분류, 객체 탐지 등의 레벨에서 Task가 달라도 되는 것인지는 서치가 필요하다.
Configuration Space Design
Random Search 등 HPO(Hyper Parameter Optimizer) 방법론을 적용할 때 아무런 기준없이 최적의 성능을 보이는 Configuration을 찾으려면 굉장히 오랜 시간이 소요됩니다. 따라서 효율적으로 실험하려면 중요한 하이퍼 파라미터는 여러가지 실험을 해보되, 중요하지 않은 하이퍼 파라미터는 적게 실험하는 것이 좋습니다.
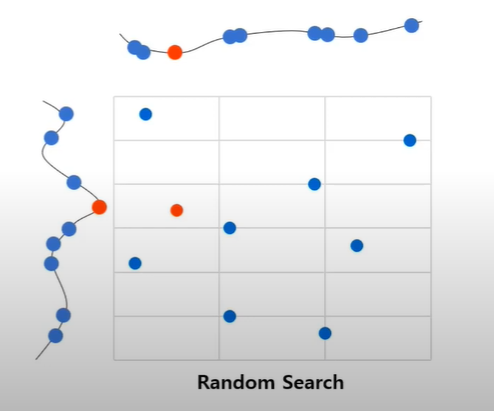
하이퍼 파라미터의 중요도를 측정하는 방식은 크게 ANOVA 분석, Performance Gain, Occurence Top-K가 있습니다. ANOVA 분석은 익히 알고 있는 분산을 추정하는 방식으로 하이퍼 파라미터의 변화에 따른 모델 성능의 분산이 클수록 중요한 하이퍼 파라미터입니다. Performance Gain은 Default Configuration(Task Independent Recommendation으로 도출)에서 특정 하이퍼 파라미터를 바꿨을 때 성능이 얼마나 상승하는지를 보고, 성능이 많이 상승할수록 중요한 하이퍼 파라미터로 간주합니다. Occurence Top-K는 Default Configuration에서 특정 하이퍼 파라미터만으로 최적의 Configuration을 찾습니다. 그리고 해당 하이퍼 파라미터를 바꿨을 때 성능이 떨어진 비율을 보고, 성능이 많이 떨어진 순으로 K개 하이퍼 파라미터를 중요하다고 간주합니다.
Configuration Transfer
Configuration Transfer는 기존에 학습했던 Task 중에 새로운 Task와 가장 유사한 Task를 찾아 그 Task의 최적 Configuration을 추천하는 방법입니다. 이때 중요한 것은 유사한 Task를 찾는 방법입니다.
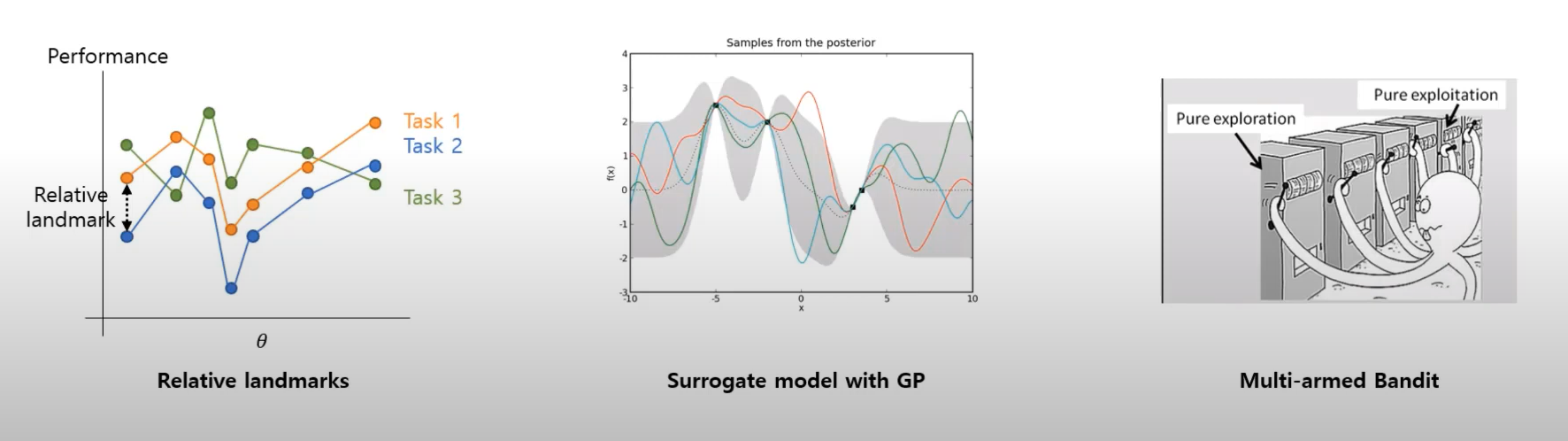

Relative Landmarks는 기존 Task에 실험했던 Configuration을 새로운 Task에도 적용해 학습해보고, Configuration 변화에 따라 성능의 변화가 비슷한 정도를 파악합니다.
Surrogate Model with GP와 Multi-armed Bandit에 대해서는 추가 서치가 필요합니다.
Learning Curve는 동일한 Configuration으로 기존 Task와 새로운 Task를 학습해보고, 학습 경과의 유사성을 비교합니다.
Learning from Meta Features
참고: https://www.youtube.com/watch?v=hTFFI6e32Nc&list=PLCsebpDZm0n6-COSyAcfr70uiUZObzF-Q&index=34
메타 피처란 데이터셋에 대한 정보입니다. General Feature, Statistical Feature, Information-Theoretical Feature 로 구분하며 구체적인 피처로는 다음과 같습니다.
| General Feature | Statistical Feature | Informataion-theoretical Feature |
| # of Instatnces | skewness | class probability |
| # of features | kurtosis | class entropy |
| # of classes | correlation | norm. entropy |
| # of missing values | covariance | mutual inform |
| # of outliers | sparsity |
Recommend Configuration
메타 피처를 Configure Tansfer의 유사도 지표를 계산하는 변수로 사용할 수 있습니다. 새로운 Task와 기존 Task의 메타 피처 사이에 유사도는 L1 Distance, 대리 모델(Surrogate Model), MLP 기반 대리 모델, L1 Distance + 베이지안 대리 모델, 베이지안 최적화, 협업 필터링 등을 이용해 구할 수 있습니다.
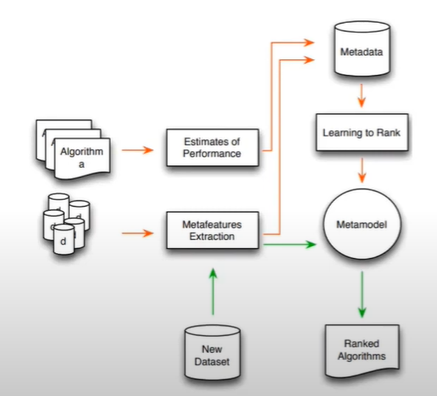
메타 피처를 활용해 기존 Configuration의 순위나 성능을 추정하는 메타 모델(Meta Model)을 학습할 수도 있습니다. 위 그림은 여러 Algorithm(=Configuration)과 d(=dataset=task)가 있을 때 메타 모델을 학습하는 과정을 설명합니다. 메타 모델은 지도 학습으로 학습하기 때문에 학습 데이터가 필요합니다. 따라서 기존의 Algorithm과 Dataset으로 추정한 학습 성능과 Dataset에서 추출한 메타 피처로 메타 데이터셋을 구성합니다. 이때 학습 성능은 Configuration에 따른 성능 순위일수도 구체적인 성능값일 수도 있습니다. 2017년에 발표한 Ranking Configuration에서는 순위를, 2018년에 발표한 Performance Prediction에서는 구체적인 성능치를 예측하는 메타모델을 학습했으며, Performance Prediction에서는 메타모델로 SVM Regressor를 사용했습니다. 새로운 데이터셋(Task)가 주어졌을 때 동일한 방식으로 메타 피처를 추출해 메타 모델의 입력값으로 사용하면, 최적의 Configuration을 구할 수 있습니다.
Pipeline Synthesis
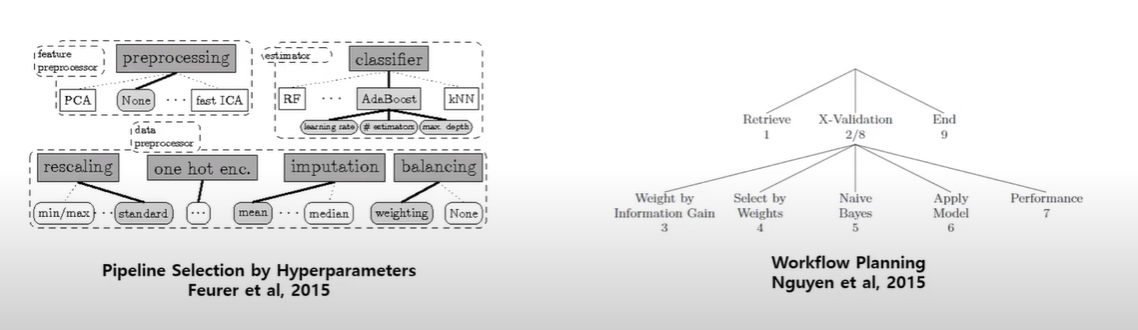

ML 모델을 학습할 때는 사람이 관여하는 것은 하이퍼 파라미터만 있는 것이 아닙니다. 전처리를 어떻게 하는지도 ML 모델 성능에 많은 영향을 줍니다. 전처리를 포함하는 ML 파이프 라인(또는 워크 플로우) 설계를 자동화하는 방안도 연구되었습니다. 메타 피처를 입력으로, 전처리 방법을 출력으로 하는 모델을 학습해 최적의 전처리 방법을 찾을 수 있습니다. 이러한 메타 모델의 아웃풋은 전처리가 필요한지, 어떤 rescale 방식을 사용해야 하는지, 원핫인코딩을 해야하는지 등을 벡터화한 값을 사용합니다. 강화 학습에도 적용 가능하다고 합니다.
Learn from Prior Experience
참고 : https://www.youtube.com/watch?v=IIc6CtarRuQ&list=PLCsebpDZm0n6-COSyAcfr70uiUZObzF-Q&index=35
이미 학습한 경험을 바탕으로 새로운 과제를 풀어나가는 것은 낯선 개념이 아닙니다. 익히 알고 있는 Transfer Learning이 대표적인 예입니다. 어떤 Task에 충분히 학습된 Neural Network를 이용해 새로운 과제를 상대적으로 적은 양의 데이터로 해결할 수 있습니다. 자연어 분야에서는 Transformer 기반의 거대 언어 모델을 Transfer Learning하는 것이 기본 값이 되었습니다.
Transfer Learning 또한 새로운 데이터셋에 대해 좋은 성능을 보이기 위해서는 많은 데이터가 필요합니다. 100개, 10개, 1개 데이터만을 활용해 새로운 데이터를 예측하기 위한 방법도 연구되고 있습니다. Few shot Learning이라고 알려진 이 분야에 대해서는 다른 글에서 더 자세히 알아보도록 하겠습니다.